The main page of my personal website features a couple of lists of data that are important or interesting to me.
The "recent posts" section shows my five most recent blog entries. Rails makes that list easy to cobble together.
The "recent listens" section shows my five most recent songs that were streamed to Last.fm. This was a little more complex to add, but after a couple of hours of back and forth with ChatGPT, I was able to put together a pretty hacky solution that looks like this:
- Check to see if your browser checked in with last.fm within the last 30 seconds.
a. If so, just show the same thing I showed you less than 30 seconds ago.
- Make a call to my server to check the recent last.fm plays.
- My server reaches out to last.fm, grabs my most recent tracks, and returns the results.
Pretty straight forward integration. I could probably do some more work to make sure I'm not spamming their API[^1], but otherwise, it was a feature that took a trivial amount of time to build and helps make my website feel a little more personal.
Meanwhile, I've been ramping up my time on my bike. I'm hoping to do something like Ragbrai or a century ride next year, so I'm trying to building as much base as I can at the moment.
Every one of my workouts gets sent up to Strava, so that got me thinking: wouldn't it be cool to see my most recent workouts on my main page?
How the heck do I get this data into my app?
Look, I've got a confession to make: I hate reading API documentation.
I've consumed hundreds of APIs over the years, and the documentation varies widely from "so robust that it makes my mind bleed" to "so desolate that it makes my mind bleed".
Strava's API struck me as closer to the former. As I was planning my strategy for using it, I actually read about a page and a half before I just said "ah, nuts to this."

Knowing my prejudice against reading documentation, this seemed like the perfect sort of feature to build hand-in-hand with a large language model. I can clearly define my output and I can ensure that the API was built before GPT-4's training data cutoff of September 2021, meaning ChatGPT is at least aware of this API even if some parts of it have changed since then.
So how did I go about doing this?
A brief but necessary interlude
In order to explain why my first attempt at this integration was a failure, I need to explain this other thing I built for myself.
I've been tracking every beer I've consumed since 2012 in an app called Untappd.
Untappd has an API[^2] which allows you to see the details about each checkin. I take those checkins and save them in a local database. With that, I was able to build a Timehop-esque interface that shows the beers I've had on this day in history.
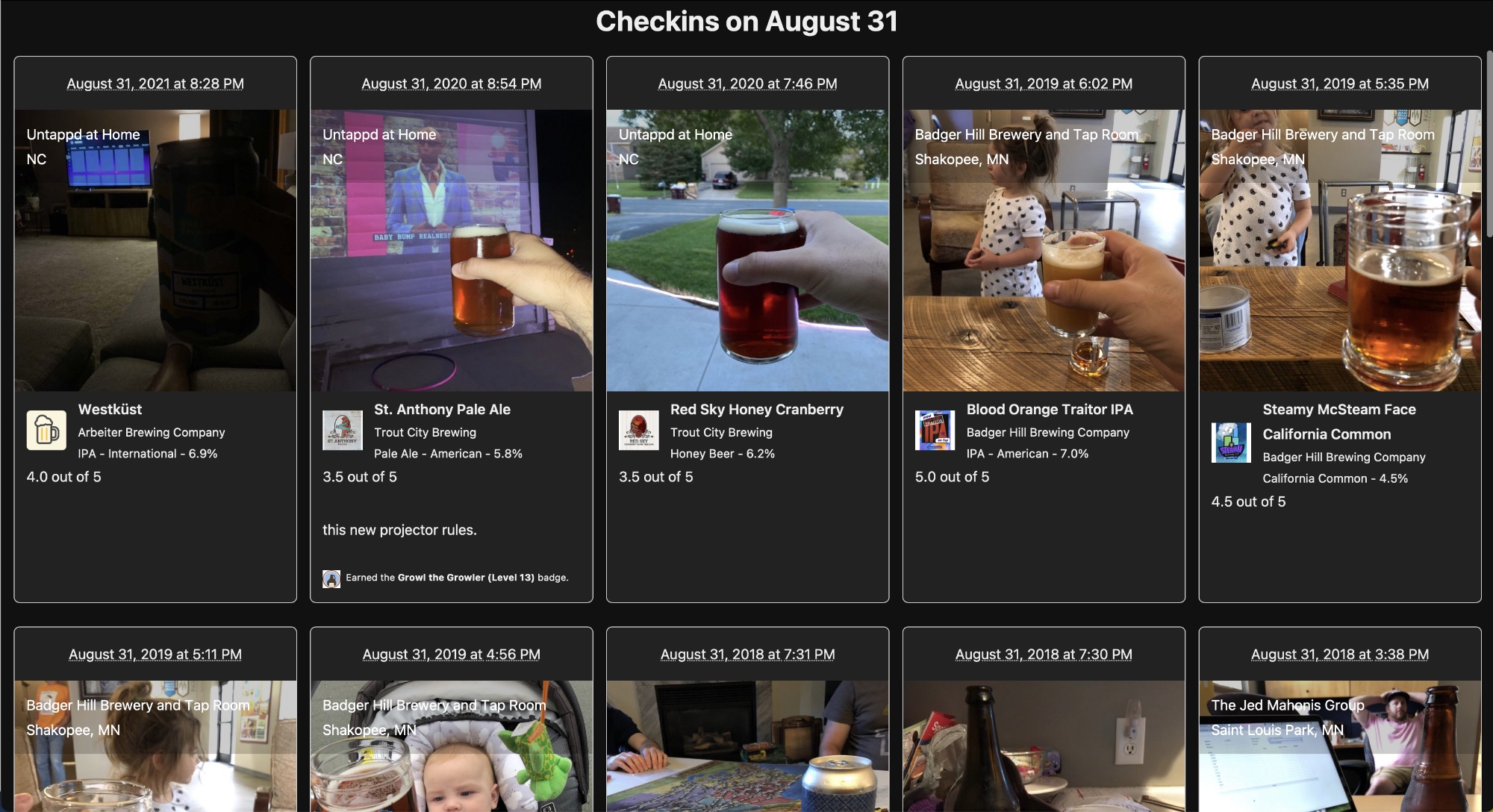
I have a scheduled job that hits the Untappd API a handful of times per day to check for new entries.[^3] If it finds any new checkins, I save the associated metadata to my local database.
Now, all of the code that powers this clunky job is embarrassing. It's probably riddled with security vulnerabilities, and it's inelegant to the point that it is something I'd never want to show the world. But hey, it works, and it brings me a great deal of joy every morning that I check it.
As I started approaching my Strava integration, I did the same thing I do every time I start a new software project: vow to be less lazy and build a neatly-architected, well-considered feature.
Attempt number one: get lazy and give up.
My first attempt at doing this happened about a month ago. I went to Strava's developer page, read through the documents, saw the trigger word OAuth, and quickly noped my way out of there.
...
It's not like I've never consumed an API which requires authenticating with OAuth before. Actually, I think it's pretty nifty that we've got this protocol that allows us to pass back and forth tokens rather than plaintext passwords.
But as a lazy person who is writing a hacky little thing to show my workouts, I didn't want to go through all the effort to write a token refresh method for this seemingly trivial thing.
I decided to give up and shelve the project for a while.
Attempt number two: Thanks, ChatGPT.
After a couple of weeks of doing much more productive things like polishing up my upcoming TEDx talk, I decided I needed a little change of context, so I picked this project back up.
Knowing that ChatGPT has my back, I decided to write a prompt to get things going. It went something like this:
You are an expert Ruby on Rails developer with extensive knowledge on interacting with Strava's API. I am working within a Rails 5.2 app. I would like to create a scheduled job which periodically grabs any new activities for a specific user and saves some of the activity's metadata to a local database. Your task is to help me create a development plan which fulfills the stated goal. Do not write any code at this time. Please ask any clarifying questions before proceeding.
I've found this style of prompt yields the best results when working on a feature like this one. Let me break it down line by line:
You are an expert Ruby on Rails developer with extensive knowledge on interacting with Strava's API.
Here, I'm setting the initial context for the GPT model. I like to think of interacting with ChatGPT like I'm able to summon the exact perfect human in the world that could solve the problem I'm facing. In this case, an expert Ruby on Rails developer who has actually worked with the Strava API should be able to knock out my problem in no time.
I am working within a Rails 5.2 app.
Yeah, I know... I really should upgrade the Rails app that powers this site. A different problem for a different blog post.
Telling ChatGPT to hone its answers down on the specific framework will provide me with a better answer.
I would like to create a scheduled job which periodically grabs any new activities for a specific user and saves some of the activity's metadata to a local database.
Here, I'm describing what should result after a successful back and forth. A senior Rails developer would know what job means in this context, but if you aren't familiar with Rails, a job is a function that can get scheduled to run on a background process.
All I should need to do is say, "go run this job", and then everything needed to reach out to Strava for new activities and save them to the database is encapsulated entirely in that job.
I can then take that job and run it on whatever schedule I'd like!
Your task is to help me create a development plan which fulfills the stated goal.
Here, I'm telling ChatGPT that I don't want it to write code. I want it to think through[^4] and clearly reason out a development plan that will get to me to the final result.
Do not write any code at this time.
The most effective way I've used ChatGPT is to first ask it to start high level (give me the project plan), then dig into lower levels as needed (generate code). I don't want it to waste its reasoning power on code at this time; I'd rather finesse the project plan first.
Please ask any clarifying questions before proceeding.
I toss this in after most of my prompts because I've found that ChatGPT often asks me some reasonable questions that challenge my assumptions.
Now, after a nice back and forth with ChatGPT, I was able to start down a path that was similar to my Untappd polling script.
As I was approaching the point where I could first test my example, I went to go read the documentation and came across an entire section that discussed webhooks.
[cue record scratch]
Wait up... webhooks?!
A sojourn into webhooks
If you've made it this far into the article, I'm assuming you're a little bit technical, but in the interest of not making assumptions, I'll briefly explain the concept of webhooks.
If you look at how I'm integrating with the Untappd API, you can see I'm periodically reaching out to their API to see if there's any new checkin activity. This method is called polling.
Webhooks are kind of the opposite: when I complete an activity within Strava, Strava can reach out to my app and say, "there's a new activity for you." Once I get that notification, I can reach out to their API to fetch the new activity details.
For my Strava app, this is a much better[^5] way of doing things. I no longer need to poll for new information; I can just wait for Strava to tell me when action needs to be taken.
But, of course, when I first told ChatGPT to help me with this solution, it didn't mention webhooks. And why would it? I never told it "give me the best solution for this problem." I said "here's my problem and a proposed solution, go ahead and give me the path forward."
I'm a bit frustrated that I didn't see the webhook option initially. I'm even more frustrated that ChatGPT only mentioned it well after we started down this path, and only after I asked it point blank:
Does Strava offer a web hook API?
Yes, Strava does offer a webhook API. Webhooks allow you to receive real-time updates about athlete activities, which can be more efficient than periodically polling for new data. Here's a brief overview of how to set up and use Strava webhooks:
[brief outline complete with things to consider with this approach]
Attempt number three: finally.
While considering my original prompt, I gave it this new one:
Okay, I'd like to incorporate webhooks into this workflow. Here's what I'd like to have happen:
1. Let's add the infrastructure in place to subscribe to webhook notifications within my Rails 5.2 app.
2. When a webhook is sent to my server, I'd like to either:
a. make a call to Strava's API to fetch that activity's information and save that information in my local database, or;
b. use the updates field to update the locally saved information to reflect the changes
Knowing this simple walkthrough, first create me a detailed development plan for setting my app to be able to fully handle webhook notifications from Strava.
What resulted here was a detailed walkthrough of how to get webhooks incorporated into my original dev plan.
As I walked through the plan, I asked ChatGPT to go into more detail, providing code snippets to fulfill each step.
There were a few bumps in the road, to be sure. ChatGPT was happy to suggest code to reach out to the Strava API, but it had me place it within the job instead of the model. If I later want to reuse the "fetch activities" call in some other part of my app, or I want to incorporate a different API call, it makes sense to have that all sitting in one abstracted part of my app.
But eventually, after an hour or so of debugging, I ended up with this:
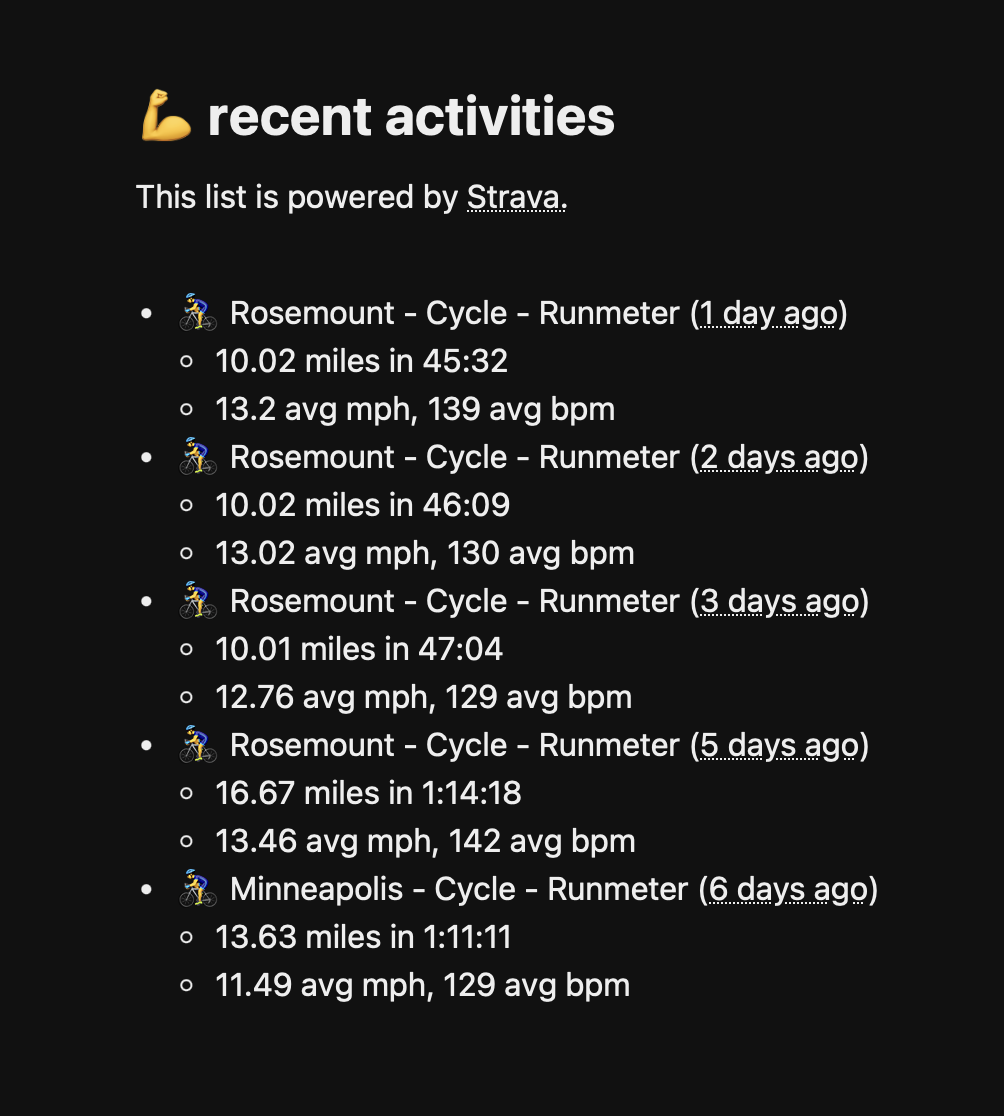
Lessons learned
I would never consider myself to be an A+ developer or a ninja rock star on the keyboard. I see software as a means to an end: code exists solely so I can have computers do stuff for me.
If I'm being honest, if ChatGPT didn't write most of the code for this feature, I probably wouldn't have built it at all.
At the end of the day, once I was able to clearly articulate what I wanted, ChatGPT was able to deliver it.
I don't think most of my takeaways are all that interesting:
- I needed to ask ChatGPT to make fixes to parts of code that I knew just wouldn't work (or I'd just begrudgingly fix them myself).
- Occasionally, ChatGPT would lose its context and I'd have to remind it who it was[^6] and what its task is.
- I would not trust ChatGPT to write a whole app unsupervised.
If I were a developer who only took orders from someone else and wrote code without having the big picture in mind, I'd be terrified of this technology.
But I just don't see LLMs like ChatGPT ever fully replacing human software engineers.
If I were a non-technical person who wanted to bust out a proof of concept, or was otherwise unbothered by slightly buggy software that doesn't fully do what I want it to do, then this tech is good as-is.
I mean, we already have no-code and low-code solutions out there that serve a similar purpose, and I'm not here to demean or denigrate those; they can be the ideal solution to prove out a concept and even outright solve a business need.
But the thing I keep noticing when using LLMs is that they're only ever good at spitting out the past. They're just inferring patterns against things that have already existed. They rarely generate something truly novel.
The thing they spit out serves as a stepping stone to the novel idea.
Maybe that's the thing that distinguishes us from our technology and tools. After all, everything is a remix, but humans are just so much better at making things that appeal to other humans.
Computers and AI and technology still serve an incredibly important purpose, though. I am so grateful that this technology exists. As I was writing this blog post, OpenAI suffered a major outage, and I found myself feeling a bit stranded. We've only had ChatGPT for, like, 9 months now, but it already is an indispensable part of my workflow.
If you aren't embracing this technology in your life yet, I encourage you to watch some YouTube videos and figure out the best way to do so.
It's like having an overconfident child that actually knows everything about everything that happened prior to Sept. 2021 as an assistant. You won't be able to just say "take my car and swing over to the liquor store for me", but when you figure out that sweet spot of tasks it can accomplish, your output will be so much more fruitful.
I'm really happy with how this turned out. It's already causing me to build a healthy biking habit, and I think it helps reveals an interesting side of myself to those who are visiting my site.
[^1]: Maybe I can cache the data locally like I'm doing for Untappd? I dunno, probably not worth the effort. ?
[^2]: Their documentation is a little confusing to me and sits closer to the "desolate" end of the spectrum because I'm not able to make requests that I would assume I can make, but hey, I'm just grateful they have one and still keep it operational!
[^3]: If we wanna get specific, I ping the Untappd API at the following times every day: 12:03p, 1:04p, 2:12p, 3:06p, 4:03p, 5:03p, 6:02p, 7:01p, 8:02p, 9:03p, 10:04p, and 12:01a. I chose these times because (a) I wanted to be a good API consumer and not ping it more than once an hour, (b) I didn't want to do it at the top of every hour, (c) I don't typically drink beers before 11am or after 11pm, (d) if I didn't check it hourly during my standard drinking time, then during the times I attend a beer festival, I found I was missing some of the checkins because the API only returns 10 beers at a time and I got lazy and didn't build in some sort of recursive check for previous beers.
[^4]: Please don't get it twisted; LLMs do not actually think. But they can reason. I've found that if you make an LLM explain itself before it attempts a complex task like this, it is much more likely to be successful.
[^5]:  [^6]:
[^6]: 

