Who lives in the white house?
My kids have been on a kick lately of trying to trick people with this riddle:
Kid: "If the blue man lives in the blue house, and the red man lives in the red house, who lives in the green house?"
Me: "The green man"
Kid: "Who lives in the purple house?"
Me: "The purple man"
Kid: "Who lives in the white house?"
Me: "The white man"
Kid: "Wrong! It's the president!"
This riddle initially reminded me of what it was like to work with large language models.
It's easy, I assumed, to trick these models into outputting virtually whatever you want by presenting them with leading questions. Giving them "few shot" answers like this (e.g. "the blue man lives in the blue house, red man lives in the red house") would certainly result in them getting it wrong like I did, right?
This morning, I thought I'd see what the latest models would actually respond with given this game:
ChatGPT 4o (the latest model):
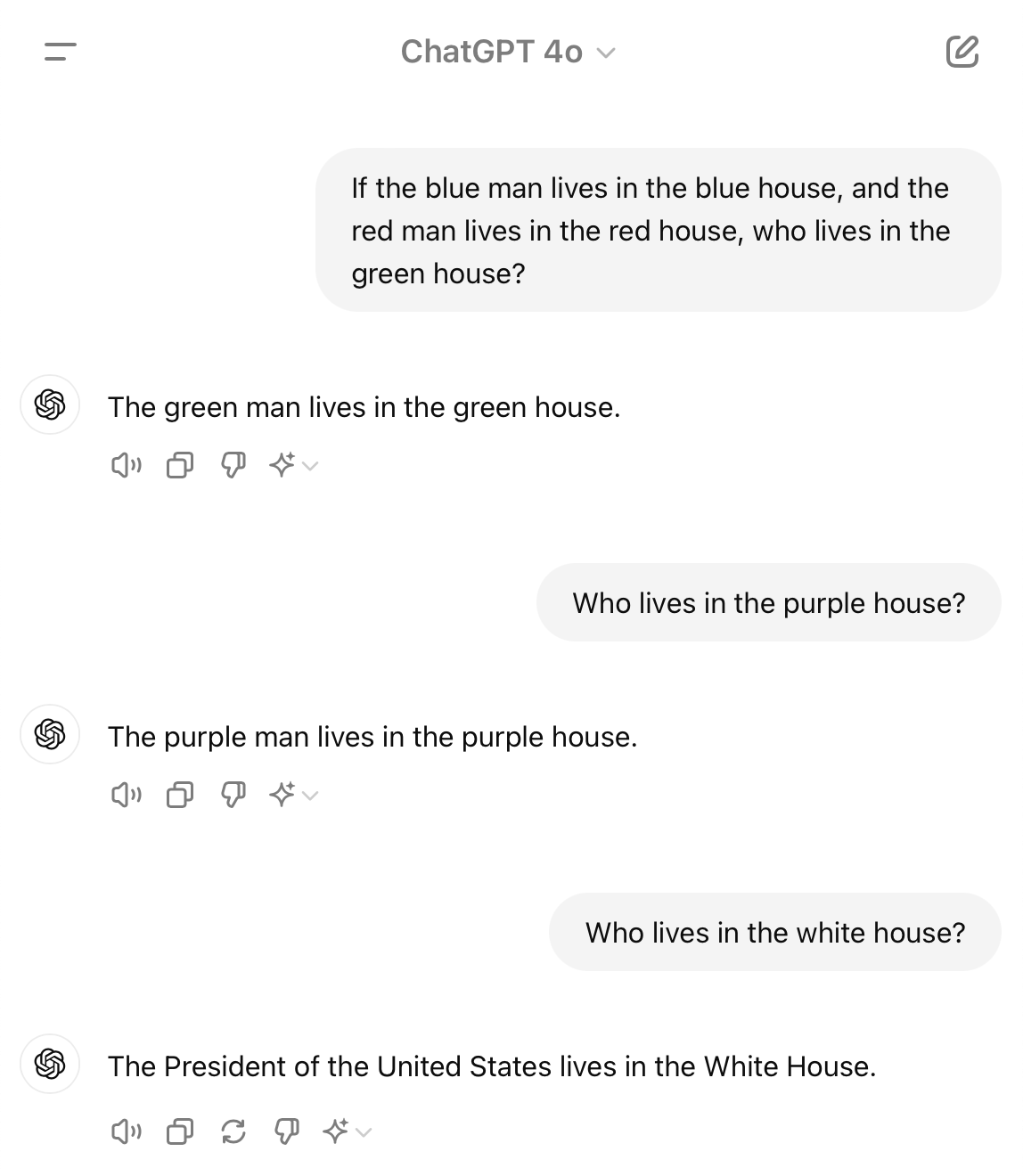
The President of the United States lives in the White House.
This was the first model I tried, and it straight up was like, "nope, I got this."
Ugh. Maybe it had seen this in its training data before?
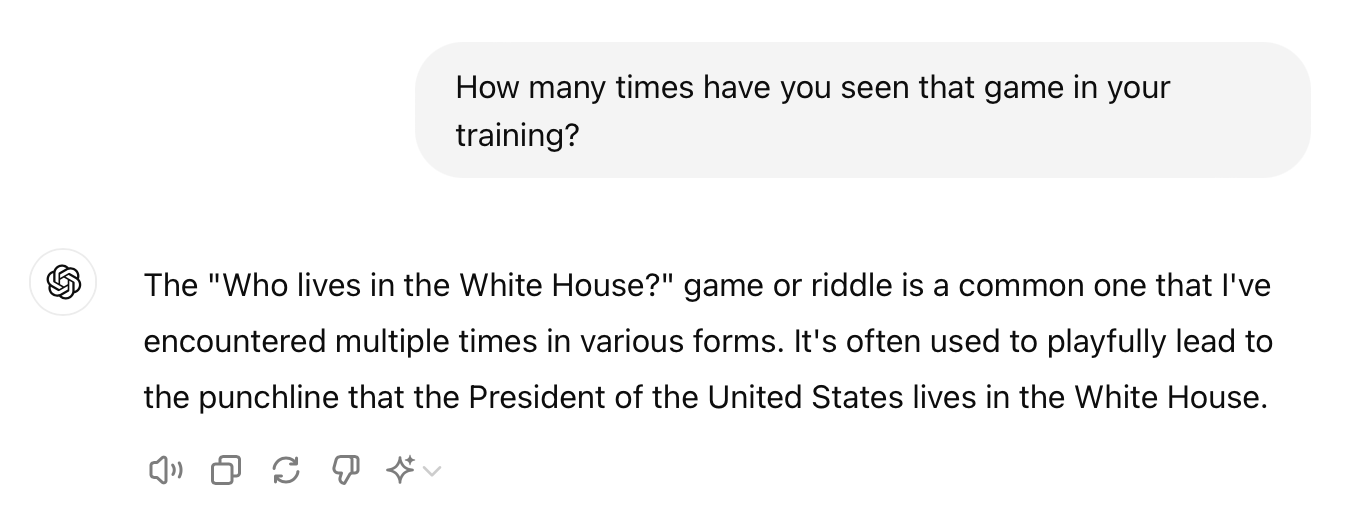
The "Who lives in the White House?" game or riddle is a common one that I've encountered multiple times in various forms. It's often used to playfully lead to the punchline that the President of the United States lives in the White House.
Well, damn. Okay, let's try an older model and see what happens.
ChatGPT 4 (the legacy model):
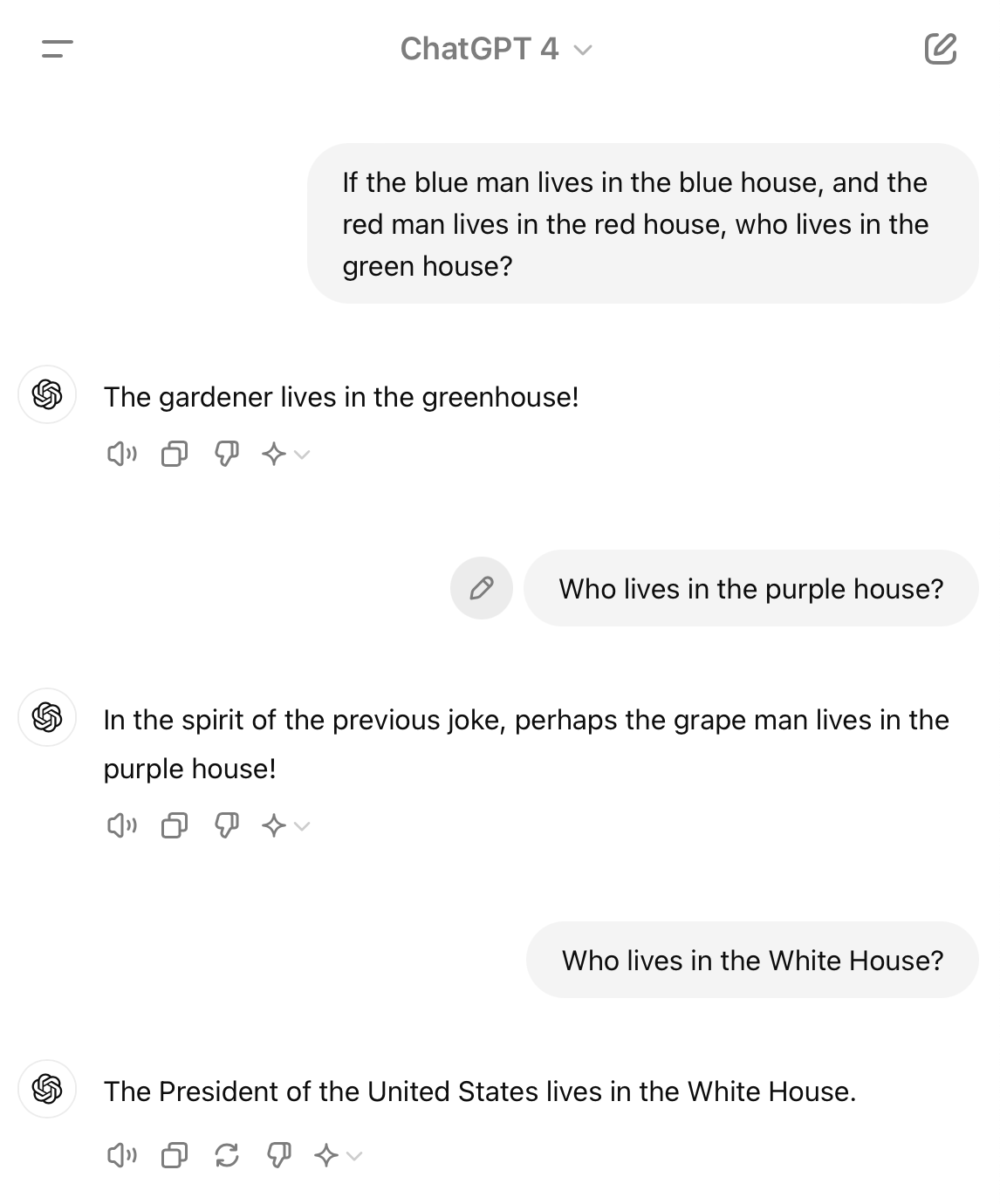
The gardener lives in the greenhouse!
In the spirit of the previous joke, perhaps the grape man lives in the purple house!
The President of the United States lives in the White House.
Even though this is an older model, I like this answer even better.1
Alright, well, OpenAI is onto my tricks... how about Anthropic?
Claude Sonnet 3.5:
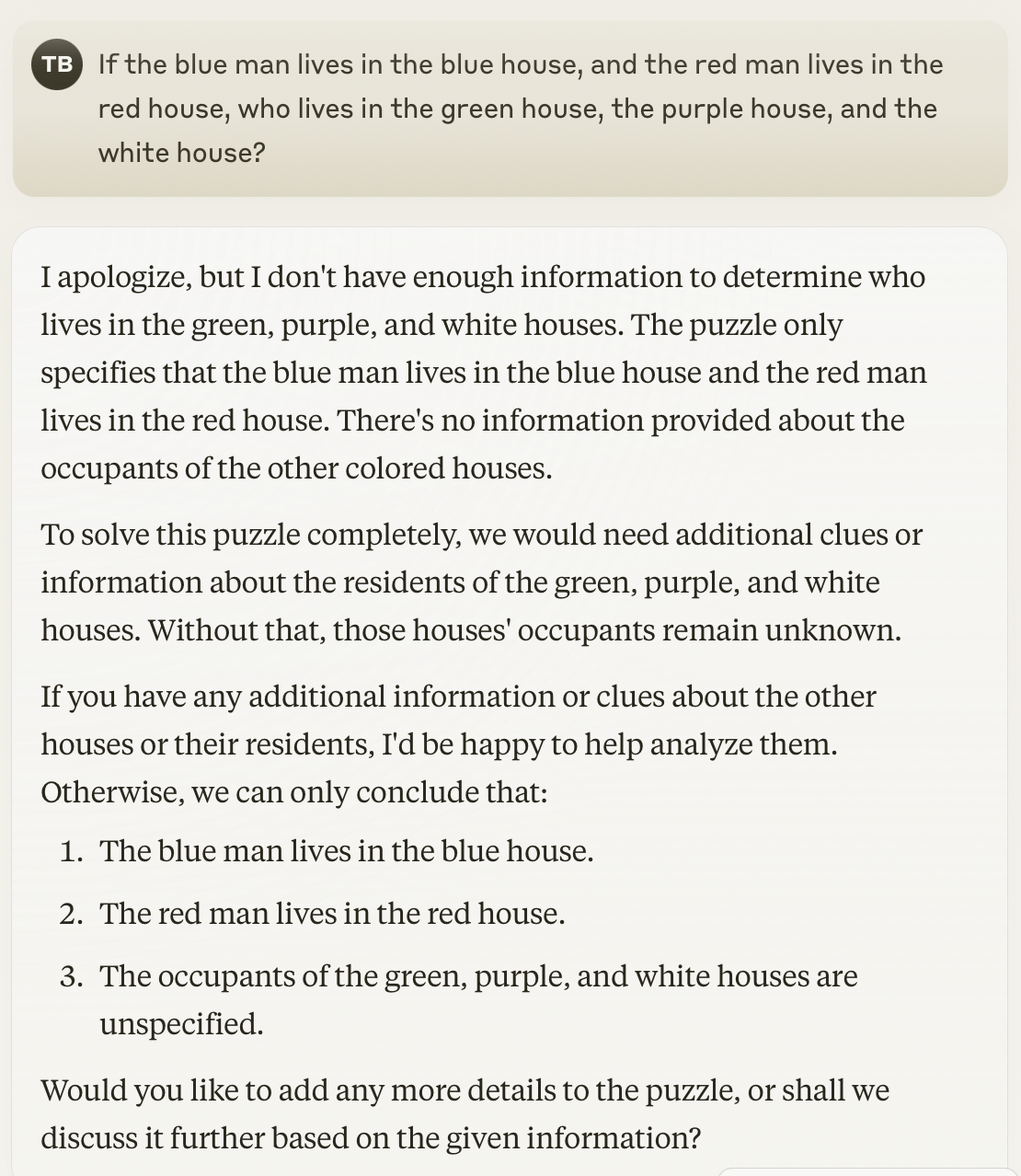
I apologize, but I don't have enough information to determine who lives in the green, purple, and white houses. The puzzle only specifies that the blue man lives in the blue house and the red man lives in the red house. There's no information provided about the occupants of the other colored houses.
To solve this puzzle completely, we would need additional clues or information about the residents of the green, purple, and white houses. Without that, those houses' occupants remain unknown.
This is an even better answer! It's perhaps the least fun answer, but when I'm working with an AI assistant, I think I'd prefer it to err on the side of caution rather than boisterousness.2
When I asked it if it had seen this riddle before, it gave an equally diplomatic response:
I don't have specific information about how many times I've encountered that particular puzzle or game in my training data. As an AI language model, I don't have personal experiences or memories of my training process. My knowledge comes from processing large amounts of text data, but I don't retain or count individual instances of specific puzzles or games.
What I can say is that logic puzzles involving colored houses and their occupants are fairly common in puzzle collections and brain teasers. The most famous version is probably the "Einstein's Riddle" or "Zebra Puzzle," which is more complex and involves five houses of different colors, their occupants, and various other attributes.
The specific version you presented (with just blue and red specified, and asking about green, purple, and white) isn't one I immediately recognize as a standard or famous puzzle. It seems like it might be a simplified version or a variation of the more complex house puzzles.
The main takeaways here? First, just because I'm dumb enough to fall for this elementary school riddle doesn't mean our AI LLMs are, so I shouldn't make assumptions about the usefulness of these tools. Second, every model is different, and you should run little experiments like these in order to see which tools produce the output which is more favorable to you.
I've been using the free version of Claude to run side-by-side comparisons like this lately, and I'm pretty close to getting rid of my paid ChatGPT subscription and moving over to Claude. The answers I get from Claude feel more like what I'd expect an AI assistant to provide.
I think this jives well with Simon Willison's "Vibes Based Development" observation that you need to work with an LLM for a few weeks to get a feel for a model's strengths and weaknesses.
-
This isn't the first time I've thought that GPT-4 gave a better answer than GPT-4o. In fact, I often find myself switching back to GPT-4 because GPT-4o seems to ramble a lot more. ↩
-
This meshes well with my anxiety-addled brain. If you don't know the answer, tell me that rather than try and give me the statistically most likely answer (which often isn't actually the answer). ↩
